
Устранение конкуренции в менеджере блокировок
Во-первых, мы исследовали влияние конкуренции в менеджере блокировок в базовой системе и прототипе DORA при использовании в них возрастающего числа аппаратных ресурсов. В этом эксперимента рабочая нагрузка генерировалась клиентами, непрерывно запрашивающими выполнение транзакции GetSubscriberData из тестового набора TM1.

Рис. 1. DORA в сравнении с традиционной системой при рабочей нагрузке, состоящей из транзакций GetSubscriberData тестового набора TM1: (a) пропускная способность в соответствии с коэффициентом использования процессора при возрастании этого коэффициента; (b) распределение времени традиционной системы; (c) распределение времени прототипа DORA.
Результаты показаны на рис. 1. На самом левом рисунке показана пропускная способность в соответствии с коэффициентом использования процессора при возрастании этого коэффициента. На двух других диаграммах показано разделение времени каждой из двух систем. Можно видеть, что конкуренция в менеджере блокировок становится узким местом базовой системы, отбирая более 85% от общего времени выполнения. В отличие от этого, в DORA конкуренция в менеджере блокировок устраняется. Как можно заметить, накладные расходы механизма DORA невелики, намного меньше тех, которые возникают при работе централизованного менеджера блокировок даже при отсутствии конкуренции. Важно заметить, что GetSubscriberData – это только читающая транзакция. И, тем не менее, базовая система испытывает серьезные трудности из-за конкуренции внутри менеджера блокировок. Это объясняется тем, что потоки управления конкурируют даже в тех случаях, когда им требуется получить одну и ту же блокировку в совместимых режимах.

Рис. 5. Блокировки, запрошенные 100 транзакциями в базовой системе и в DORA при трех рабочих нагрузках.
Далее мы численым образом оценивали, насколько эффективно DORA сокращает число взаимодействий с централизованным менеджером блокировок, и как это влияет на производительность. Мы измеряли число блокировок, запрашиваемых в базовой системе и в DORA.
Мы инструментировали код для сбора данных о числе и типе запрашиваемых блокировок. На рис. 5 показано число блокировок, запрошенных 100 транзакциями при выполнении обеими системами транзакций из тестовых наборов TM1 и TPC-B, а также транзакции OrderStatus из TPC-C. Блокировки разбиваются на три типа: блокировки уровня записей, блокировки центрального менеджера блокировок, не являющиеся блокировками уровня записей (на рисунке они обозначены как "higher level"), и локальные блокировки DORA.
При типичной рабочей нагрузке OLTP конкуренция за блокировки уровня записей имеет ограниченный характер, поскольку имеется очень большое число записей, доступ к которым происходит случайным образом. Но по мере продвижения вверх по иерархии блокировок можно ожидать возрастания уровня конкуренции. Например, каждой транзакции требуется получить блокировки намерений на уровне таблиц. На рис. 5 показано, что в DORA имеются лишь минимальные взаимодействия с централизованным менеджером блокировок. При выполнении тестового набора TPC-B в DORA запрашивается блокировка не уровня записей из-за управления областью хранения данных (выделения новой области страниц).
Рис. 5 позволяет составить некоторое представление о поведении этих трех рабочих нагрузок. TM1 состоит из исключительно кратковременных транзакций. Для их выполнения в традиционной системе запрашивается столько же блокировок более высокого уровня, сколько и блокировок уровня записей. В TPC-B число блокировок уровня записей в два раза больше числа блокировок более высокого уровня. Следовательно, можно ожидать, что при выполнении тестового набора TPC-B конкуренция в менеджере блокировок традиционной системы должна быть меньше, чем при выполнении тестового набора TM1. При выполнении транзакций OrderStatus традиционная система должна масштабироваться еще лучше, поскольку в них число блокировок уровня записей еще больше числа блокировок более высокого уровня.

Рис. 6. Производительность базовой системы и DORA при возрастании загрузки системы при выполнении транзакций тестовых наборов TM1 и TPC-B, а также транзакций OrderStatus из TPC-C.
Рис. 6 подтверждает эти ожидания. Мы представляем диаграммы производительности обеих систем при трех рабочих нагрузках. На оси абцисс показана предлагаемая загрузка процессора. Предлагаемая загрузка процессора вычисляется путем сложения измеряемого времени использования процессора и времени, которое потоки управления тратят на ожидание ресурса процессора в очереди потоков управления, готовых к выполнению. Мы видим, что базовой системе свойственны проблемы масштабируемости, наиболее серьезные в случае TM1. С другой стороны, производительность DORA масштабируется настолько хорошо, насколько это позволяют аппаратные ресурсы.
Когда предлагаемая загрузка процессора превышает 100%, производительность традиционной системы на всех трех рабочих нагрузках резко падает. Это происходит из-за того, что операционной системе приходится вытеснять потоки управления с процессора, и в некоторых случаях это происходит в середине конфликтных критических участков. С другой стороны, производительность DORA остается высокой; это еще раз доказывает, что в DORA число конфликтных критических участков уменьшается.
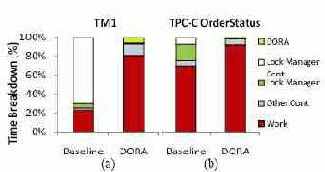
Рис. 2. Распределение времени традиционной системы обработки транзакций и прототипа DORA при полном использовании всех 64 аппаратных контекстов чипа Sun Niagara II при пропуске (a) тестового набора TM1 и (b) транзакций OrderStatus тестового набора TPC-C.
Рис. 2 показывает детальное распределение времени обеих систем при стопроцентном использовании процессора для рабочих нагрузок TM1 и OrderStatus тестового набора TPC-C. DORA превосходит по производительности базовую систему на рабочих нарузках OLTP независимо от того, имеются или нет конфликты в менеджере блокировок базовой системы.